
(图片来源:摄图网)
4月29日破晓,阿里巴巴在环球野生智能范畴投下一枚重磅炸弹——新一代通义千问模型Qwen3(千问3)正式开源发布。千问3是环球首个“混淆推理模型”,将“快思索”与“慢思索”集成到统一个模型中。这就好比为模型配备了一个“伶俐大脑”,既能像人类快速反应一样迅速处理简朴任务,又能像深思熟虑的智者一样精准应对庞大问题,实现了推理效率与质量的完满均衡。参数目仅为DeepSeek-R1的三分之一,但性能全面超出R1、OpenAI-o1等环球顶尖模型,成为环球最强开源模型。
千问3包含8款不同尺寸的模型,其中,旗舰模型Qwen3 - 235B - A22B总参数目为235B,激活仅需22B,创下所有国产模型及环球开源模型的性能新高。该模型预锻炼数据量达36T,犹如一个知识渊博的“超级学者”,经过海量数据的进修和后锻炼阶段的多轮强化进修,在推理、指令遵守、对象调用、多语言本领等方面均实现了大幅增强。
展开剩余 72 %千问3在部署成本大幅下落,仅需4张H20显卡即可部署满血版,这一特性大大降低了企业和开发者利用大模型的门坎,让更多人能够或许享用到先进AI技能带来的盈余。而且,千问3支持119种语言,采用Apache 2.0协议开源,环球开发者、研讨机构和企业能够在魔搭社区、HuggingFace等平台收费下载并商用,个人用户也能够通过通义APP轻松体验,真正实现了AI技能的开放共享与普惠。
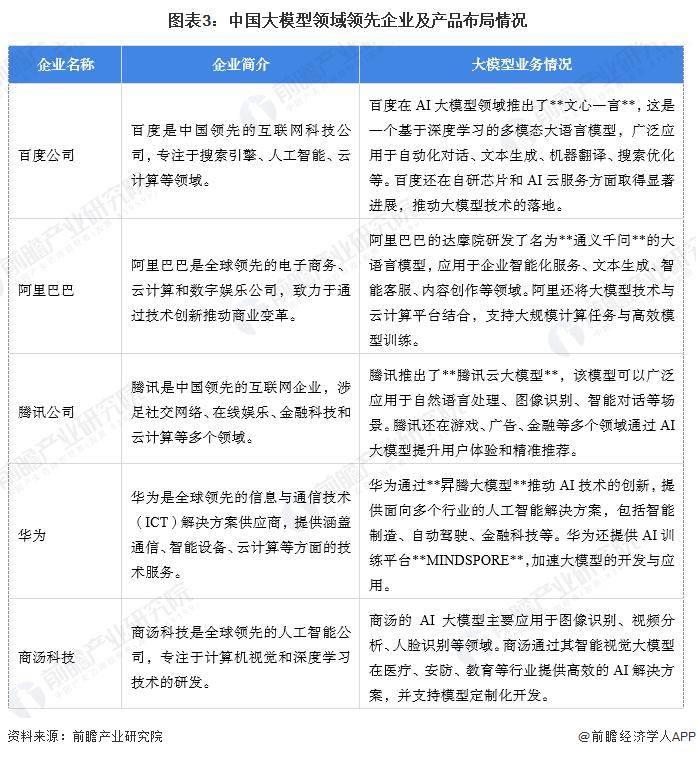
我国大模型发展经历了三个主要阶段。早期索求阶段(2000年代初至2010年代初)主要集中在基础AI理论和小规模运用的研讨,缺乏大规模数据和高性能较量争论资本。随着2012年深度进修的兴起,我国大模型发展迎来了快速发展的黄金期间(2010年代初至2020岁首年月)。国内大企业如阿里巴巴、百度、腾讯和华为敏锐地捕捉到了AI技能的巨大潜力,开始鼎力大举投资AI技能。它们凭借雄厚的资金气力和壮大的科研团队,推动了大模型技能的发展和运用。这一期间,我国大模型在图象辨认、语音辨认等范畴取得了一系列重要冲破,渐渐在国际舞台上崭露头角。到了成熟与运用阶段(2020岁首年月至今),我国在天然语言处理和较量争论机视觉等范畴的大模型技能已达到国际先进程度,模型广泛运用于贸易、医疗、执法等多个行业。
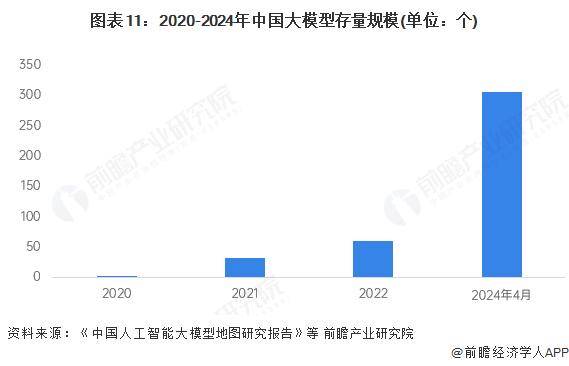
数据表现,截至2024年4月,国内已涌现出305个大模型,其中254个具备10亿参数级以上规模,构成以阿里、百度、腾讯、华为等科技巨子为引领,商汤、云从等垂直范畴新锐为增补的竞争格局。这种“头雁领航、群雁齐飞”的态势,正推动我国在天然语言处理、较量争论机视觉等枢纽范畴持续连结环球第一梯队的技能优势。千问3的横空出世不但代表着我国大模型在工程化本领上的冲破。

以后环球的野生智能家当处于高速发展期,大模型技能引领着野生智能范畴正在迈向新的发展高度。前瞻家当研讨院开端测算,到2030年,我国大模型市场规模将超过2200亿元,年复合增速在40%以上。
前瞻经济学人APP资讯组
更多本行业研讨阐明详见前瞻家当研讨院《》
同时前瞻家当研讨院还提供、、、、、、、、、、、等解决方案。如需转载引用本篇文章内容,请说明资料来源(前瞻家当研讨院)。
发布于:广东省![[要闻]让爱与健康同行——科学应对男性健康,重燃亲密火花](/images/news_pic/17.jpg)
![[万象]搜狐医药 | “牛奶咖啡斑”下的生命之困!神经纤维瘤病诊疗困境如何解?](/images/news_pic/10.jpg)
![[动态]365位医师的365天 | 官键:用好放疗这把刀,帮助患者活得久活得好](/images/news_pic/9.jpg)
![[社会]搜狐健康课·预告 | 如何养肝护肝?这份“肝”货请收好](/images/news_pic/1.jpg)
![[视野]直播预告 | 顿顿“减肥餐”难吃还不掉秤?你做错了啥?](/images/news_pic/27.jpg)
![[动态]2025五道口金融论坛 | 迈克尔·斯宾塞谈“关税战”:没有人希望在互相伤害的道路上走下去](/images/news_pic/30.jpg)
![[视野]夏天上课整一个这个100档风扇真的太爽了 #风扇风扇大热天 #风扇 #宿舍 #提升幸福感好物](/images/news_pic/22.jpg)
![[推荐]#家用电风扇 #合立两用电风扇 #工厂直发品质保障 #遥控落地电风扇 #美的轻音电风扇](/images/news_pic/28.jpg)
![[环球]天呐!这老板卖完这一波就倒闭了吧!这价格就到手一个超大号的兔子垃圾桶真的惊呆了!它不仅是垃圾桶还是收纳桶、装饰摆件哈!#垃圾桶](/images/news_pic/18.jpg)
![[新闻]【央视快评】勇敢克服困难挑战 积极追求人生梦想](/images/news_pic/29.jpg)
![[推荐]酷小麦自制儿童剧《缇娜托尼·星星的秘密》北京开启驻演 九首原创歌曲获赞](/images/news_pic/24.jpg)
![[奇闻]三位跨世纪奶奶的长寿心法 这几点惊人的相似](/images/news_pic/19.jpg)
