雷递网 乐天 5月26日
红杉中国本日正式推出一款全新的AI基准测试工具xbench,并发布论文《xbench: Tracking Agents Productivity,Scaling with Profession-Aligned Real-World Evaluations》。
红杉中国称,在评价和推动AI系统提升能力上限与技术边界的同时,xbench会重点量化AI系统在实在场景的效用价值,并采纳长青评价的机制,去捕捉Agent产品的枢纽突破。

据介绍,随着基础模型的快速进展和AI Agent进入规模化应用阶段,被遍及使用的基准测试(Benchmark)却面对一个日益尖利的成绩:想要实在地反应AI的客观能力正变得越来越困难。
因此,构建更加科学、长效和如实反应AI客观能力的评测系统,正在成为指引AI技术突破与产品迭代的紧张需求。
展开剩余 77 %据介绍,xbench采纳双轨评价系统,构建多维度测评数据集,旨在同时追踪模型的理论能力上限与Agent的实际落地价值。
该系统创新性地将评测使命分为两条互补的主线:(1)评价AI系统的能力上限与技术边界;(2)量化AI系统在实在场景的效用价值(Utility Value)。其中,后者需要静态对齐实际世界的应用需求,基于实际工作流程和具体社会脚色,为各垂直领域构建具有明白业务价值的测评标准。
xbench采纳长青评价(Evergreen Evaluation)机制,通过持续维护并静态更新测试内容,以确保时效性和相关性。我们将按期测评市场主流Agent产品,跟踪模型能力演进,捕捉Agent产品迭代过程中的枢纽突破,进而预测下一个Agent应用的技术-市场契合点(TMF,Tech-Market Fit)。作为独立第三方,我们致力于为每类产品设计公允的评价情况,提供客观且可复现的评价结果。
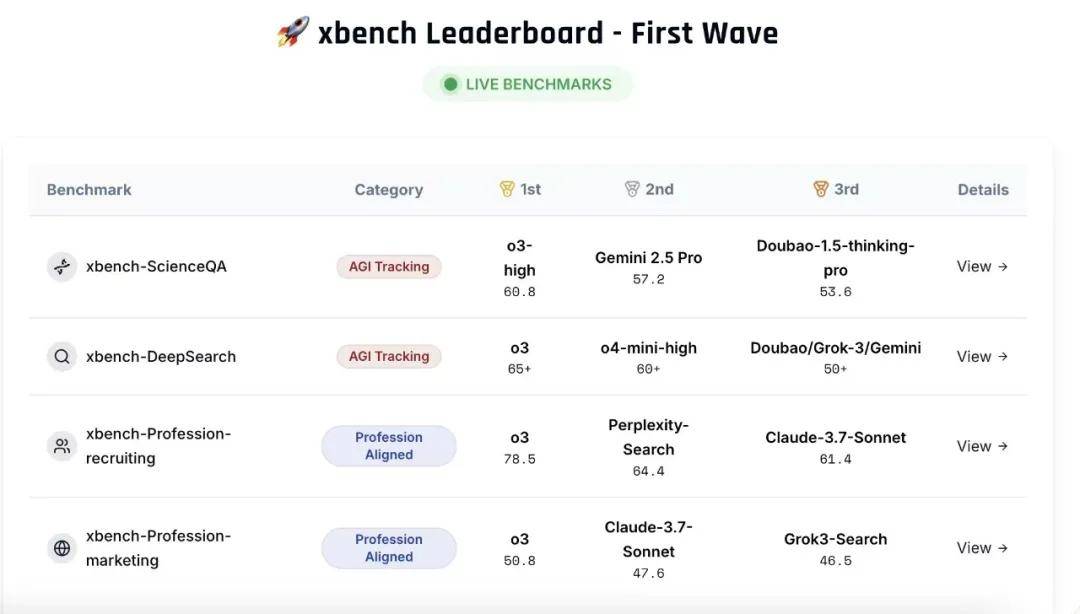
首期发布包含两个核心评价集:科学成绩解答测评集(xbench-ScienceQA)与中文互联网深度搜索测评集(xbench-DeepSearch),并对该领域主要产品进行了综合排名。同期提出了垂直领域智能体的评测方法论,并构建了面向招聘(Recruitment)和营销(Marketing)领域的垂类Agent评测框架。评测结果和方法论可通过xbench.org网站实时查看。
在过去两年多的时间里,xbench不停是红杉中国在内部使用的跟踪和评价基础模型能力的工具。
红杉中国称,2022年ChatGPT推出后,红杉中国最先对AGI进程和主流模型实行每个月的评测与内部汇报。2023年3月,红杉中国最先建设xbench的第一批公有题库,题目类型主要针对Chatbot简单问答及逻辑思索。
2025年3月,红杉中国最先第三次对xbench题库进行进级,思索两个核心成绩:
1/ 模型能力和AI实际效用之间的关系:我们出越来越难的题目意义是什么,是否落入了惯性思维?AI落地的实际经济价值真的和AI会做困难正相关吗?举个例子,程序员工作的Utility Value很高,但AI做起来进步异常快,而“去工地搬砖”这样的工作AI却几乎没法完成。
2/ 不同时间维度上的能力对照:每一次xbench换题,我们便失去了对AI能力的前后可比性追踪,因为在新的题集下,模型版本也在迭代,我们没法对照不同时间维度上的单个模型的能力怎样变化。在判断创业项目标时候,我们喜欢看创业者的“成长斜率”,但在评价AI能力这件事上,我们却因为题库的不断更新而没法无效判断。
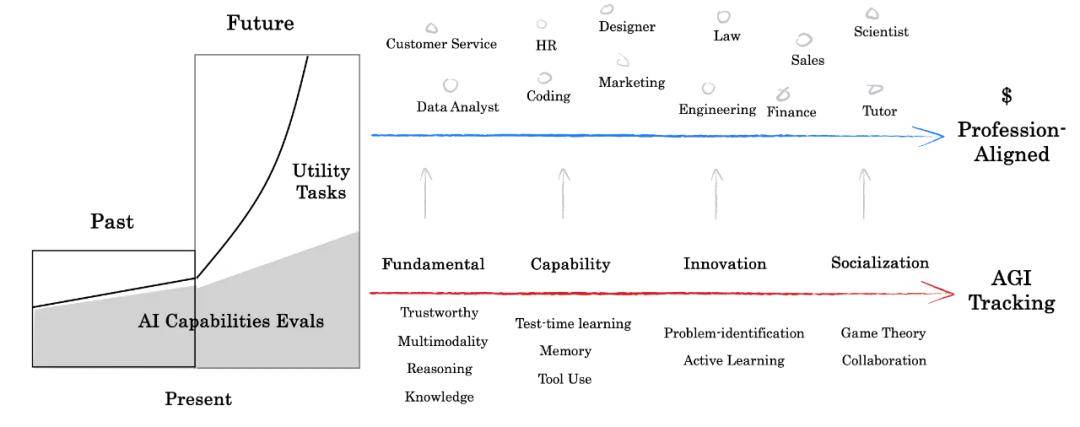
红杉中国引入Profession Aligned的基准观点,认为评价会分为AGI tracking与Profession Aligned,AI将面对更多复杂情况下效用的考察,从业务中收集的静态题集,而不单是更难的智力题。
静态评价集一旦面世,会涌现题目泄露导致过拟合然后迅速失效的成绩。红杉中国称,将维护一个静态更新的题目扩充评价集来缓解这一现象。
 xbench-ScienceQA: 考察基础智能-学问
xbench-ScienceQA: 考察基础智能-学问
红杉中国称,这一次发布的xbench-ScienceQA与xbench-DeepSearch评价属于Knowledge与Tool Use的子类别,测试Agent在这两项主能力分类下的子使命能力。
———————————————
雷递由媒体人雷建平创办,若转载请写明来源。
发布于:北京市![[万象]就医帮 | 高龄心脏“满血复活”!北京地坛医院心内科为高龄重症心衰患者实施TEER手术](/images/news_pic/17.jpg)
![[新闻]搜狐名医 | 北肿沈琳:得胃癌的年轻人为何越来越多?](/images/news_pic/8.jpg)
![[新闻]科普专家说慢病·精编 | 甲状腺微小癌适合做消融吗?](/images/news_pic/26.jpg)
![[奇闻]直播预告 | 孩子总尿床,是病吗?](/images/news_pic/4.jpg)
![[视野]搜狐健康大连麦·精编 | 减重误区四:催吐,易腐蚀食道牙齿](/images/news_pic/7.jpg)
![[社会]三重变革已至 “旅游 ”可期](/images/news_pic/28.jpg)
![[环球]负债攀升存货高企 华新精科闯关IPO](/images/news_pic/14.jpg)
![[奇闻]商务部:支持国家级经开区开发建设主体上市融资](/images/news_pic/29.jpg)
![[生活]刘宽忍被查,陕西省委表态:坚决拥护党中央决定](/images/news_pic/2.jpg)
![[动态]马上评|从最高法治理“挂床”,再看王佳佳法官遇害案](/images/news_pic/22.jpg)
![[热点]重组胶原蛋白含量到底多少?巨子生物可复美陷入造假争议,公司否认造假](/images/news_pic/23.jpg)
