多模态大模型行业是指围绕能够处理、明白和天生多种类型数据(如文本、图象、音频、视频等)的深度进修模型所构成的产业生态。这些模型经过融合没有同模态的信息,能够实行更复杂和智能的任务,例如视觉问答、图文天生、语音辨认与分解等。
多模态大模型的核心正在于跨模态语义对齐,即经过技术手段实现没有同模态数据之间的无缝毗邻和明白。这类能力使其正在多个领域具有广泛的应用潜力,包括但没有限于自然语言处理、图象辨认、语音辨认、智能驾驶、医疗影像诊断等行业主要上市公司:阿里巴巴(09988.HK,BABA.US);百度(09888.HK,BIDU.US);腾讯(00700.HK,
TCEHY);科大讯飞(002230.SZ);万兴科技(300624.SZ);三六零(601360.SH);昆仑万维(300418.SZ);云从科技(688327.SH);拓尔思(300229.SZ)等
多模态大模型产业链全景梳理
多模态大模型产业链是一个巨大而复杂的系统,涵盖了从硬件设施到软件开发的各个环节,主要包括基础层、模型层和应用层。其中,基础层主要包括硬件和基础软件,模型层主如果多模态大模型的种类,包括CLIP、BLIP、BLIP-2、dreamLLM、LLaMA、LLaVA、flamingo、mini-GPT4等,应用层则是指大模型连系行业的进一步进级应用构成的行业大模型,主要包括临盆制造领域、生活文娱领域和大众办事领域等。
展开盈余 69 %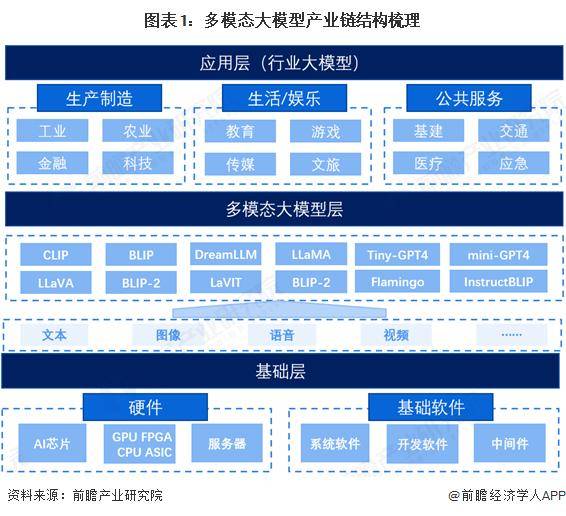
多模态大模型产物成本情况
当前海内支流大模型的锻炼成本广泛正在数千万至数亿美圆级别,其中百度文心、阿里通义、腾讯混元等大厂模型投入最高,基础超2亿美圆;而创业公司如Kimi、DeepSeek等经过技术优化降低锻炼成本,现在正在3000-6000万美圆之间。云托管成本受模型规模影响显著,大厂通常依托自有云平台,降低成本,如阿里云PAI、华为云等。而初创公司依附多云弹性部署。多模态大模型产物的成本情况以下:

全球多模态大模型行业发展进程
全球大模型产业的发展经历了初期探索期(1956年-2005年),正在这一阶段,人工智能学科出生,神经收集模型最先发展。随后进入疾速发展时间(2006年-2019年),深度进修观点被从新引入,Transformer等模型推进了行业进步。2020年至2022年为大模型兴起期,参数规模疾速扩展,2022年更被视为大模型元年。从2023年最先,大模型进入广泛应用期,其正在各领域的深度应用获得赓续拓展。这一历程并不是严格分期,而是体现了大模型技术发展的一连性和阶段性。

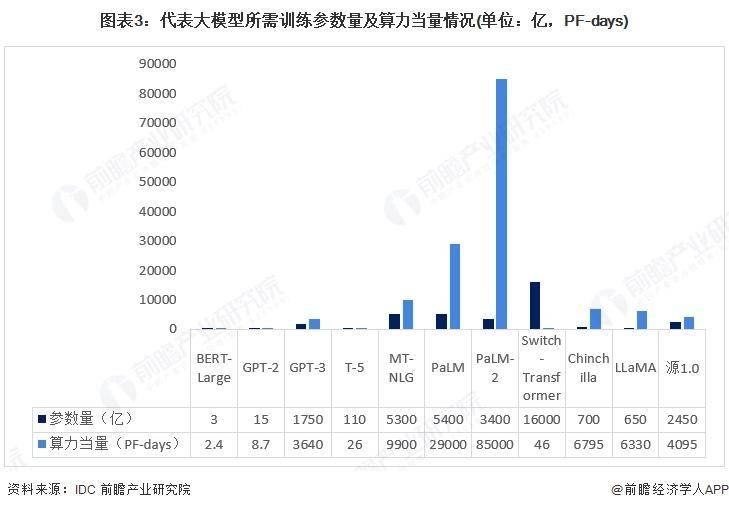
全球大模型算力需求情况
从感知智能到天生式智能,人工智能越来越需要依附“强算法、高算力、大数据”的支撑。模型的大小、锻炼所需的参数量等因素将间接影响智能出现的质量,人工智能模型需要的精确性越高,锻炼该模型所需的计算力就越高。以ChatGPT模型为例,公开数据表现,其所利用的GPT-3大模型所需锻炼参数量为1750亿,算力消耗为3640PF-days(即每秒运算一千万亿次,运行3640天),需要至多1万片GPU供应支撑。据统计,当模型参数扩展十倍,算力投入将凌驾十倍,模型架构、优化效率、并行处理能力以及算力硬件能力等因素均会影响具体添加的倍数。
更多本行业研究分析详见前瞻产业研究院《全球及中国多模态大模型行业发展前景与投资计谋计划分析报告》
同时前瞻产业研究院还供应产业新赛道研究、投资可行性研究、产业计划、园区计划、产业招商、产业图谱、产业大数据、伶俐招商系统、行业地位证实、IPO咨询/募投可研、专精特新小巨人申报、十五五计划等解决方案。如需转载引用本篇文章内容,请注明资料泉源(前瞻产业研究院)。
发布于:广东省![[奇闻]狐大医 | 长期少吃主食反而更难瘦!减重期间科学吃碳水有妙招](/images/news_pic/9.jpg)
![[热点]让爱与健康同行——科学应对男性健康,重燃亲密火花](/images/news_pic/12.jpg)
![[社会]搜狐医药 | “牛奶咖啡斑”下的生命之困!神经纤维瘤病诊疗困境如何解?](/images/news_pic/20.jpg)
![[聚合]365位医师的365天 | 官键:用好放疗这把刀,帮助患者活得久活得好](/images/news_pic/17.jpg)
![[生活]使美元走弱是美国的单边政策](/images/news_pic/22.jpg)
![[推荐]《中国金融政策报告2025》提金融改革五项重点](/images/news_pic/23.jpg)
![[要闻]重磅消息!民营经济促进法正式出台,护航民营经济发展【附民营经济代表企业分析】](/images/news_pic/19.jpg)
![[要闻]鼓励大家消费!清华大学李稻葵建议:五一拿身份证消费就减免25%,1块钱补贴能拉动4块钱消费【附五一黄金周旅游分析】](/images/news_pic/7.jpg)
![[奇闻]前瞻全球产业早报:810亿国债支持以旧换新](/images/news_pic/4.jpg)
